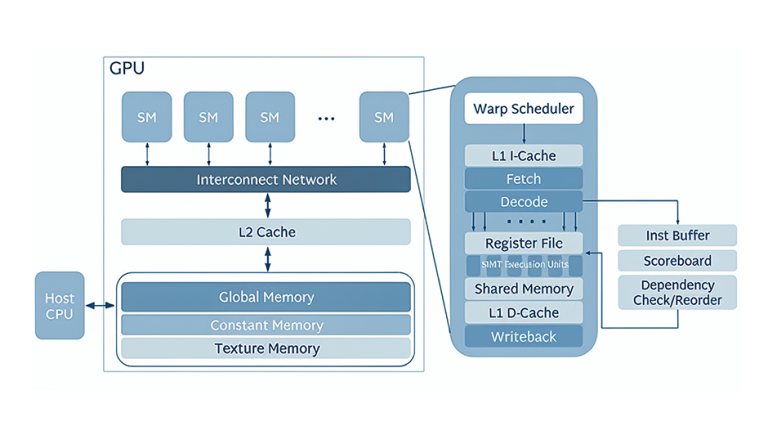

End-to-End Architecture Design – can be enabled across all the cloud environments
Workload Profiling and Rightsizing – right GPU recommendations & optimization of VM/bare metal deployments

High-Performance Network Expertise – RDMA over Converged Ethernet (RoCE) and Cluster-Aware Scheduling implementations

Automated Provisioning and Scaling – auto-scaling clusters and Infrastructure-as-Code (IaS)

Data Pipeline Optimization – high-throughput storage by design and dataset training

AI/MLOps Integration – deployment of MLOps pipelines for automated model training, versioning, and deployment
- Finance
- Retail
- Healthcare
- FMCG
- EdTech & Energy
- Media & Entertainment
- Public Sector

Notable health agency marries workloads for rapid ETL, HR, and warehousing

Healthtech player tightens security of its hybrid-cloud environment
Legendary healthcare firm replatforms EHR to save ~10mn/yr Opex

Top financial firm trades poor IT performance for unlimited productivity

Global fintech adopts Exadata to support expansion and performance

Finance industry leader migrates workloads to cloud seamlessly

Auto finance player checkmates manual operational inefficiency with automation

Billion-dollar insurance firm adopts microservices to amplify efficiency

Lifestyle retailer injects cloud into on-prem infra to beat public cloud security concerns

Hightech provider improves reporting efficiencies by 10-fold within 30 days

Retailer with 15k+ stores procures cost-effective, cloud-based disaster recovery

FMCG player lifts and shifts CRM and ERP workloads to cloud

Non-profit corporation adopts visionary, cloud-based HR platform

Manufacturer achieves seamless management and optimized efficiency across 18+ plants

A global new-age education industry leader revisits people strategy

Energy enterprise opts for cloud database to reduce on-prem data center footprint

Social media pioneer sets new standards for data governance & security analytics

Fortune 100 brand unplugs legacy apps for scale and new data competency

K-12 intermediate unit goes live with cloud-native business operations



