
Embracing cloud-based solutions and microservices-based architectures have boosted the demand for distributed databases. This hall of fame with distributed databases that have the capacity to manage heavy datasets along with maintaining scalability, flexibility, and compatibility with contemporary application designs and architectures. As the quest for innovative databases is on the edge, businesses also adopt the wiser and powerful database strategies that make scaling simple. Architected to facilitate extreme scalability, data durability, high availability, handling transactional volume at high speeds, and many other features, these are tended to accelerate value in multiple ways.
Moreover, scaling the databases must bring in resiliency as businesses must thrive in the future and capable of handling failures. All these together is enabling the enterprises to adopt next-gen technologies that Oracle has evolved into with – Distributed Database. It functions as a data distribution system with its advanced features such as database partitioning thus delivering exceptional performance, availability, and scalability.
Overview of Raft Replication
Oracle Database 23ai has a top-end feature with a name – Raft Replication, a consensus-based replication protocol that automates configuration of replication across all shards. Raft Replication seamlessly caters to applications with high transparency in operations. When shard hosts fail or rapid changes happen in the distributed database’s composition, Raft Replication reconfigures all the replication settings, with no manual work. The system itself decides to configure the replication factor, ensuring specified number of replicas are available on a consistent basis.
When Raft Replication is activated, a distributed database has multiple replication units. A replication unit (RU) is a stack of chunks that have the same replication topology. Each RU has a number of replicas located on various shards. The Raft consensus protocol streamlines consistency between the replicas whenever there are failures, network partitioning, message loss, or delays.
This article delves into components of Raft Replication and INFOLOB-led key differentiators that enhances your database performance in most reliable ways:
Features of Raft Replication
- GDSCTL Command Line Interface: A straightforward tool to enable and manage Raft replication with ease.
- Fast, Zero-Loss Failover: Automatic failover happens in a flash, ensuring no data slips through the cracks.
- Active-Active Design: All shards support read/write operations, eliminating the need for primary or standby distinctions—everyone’s on equal footing.
- Self-Managing Replicas: Whether a shard fails, joins, or leaves, Raft replication adjusts configurations on the fly.
Components of Raft Replication
Replication Unit (RU)
Think of a replication unit as a clone of a primary shard. When Raft replication is enabled in 23ai, these units spring to life. Each RU is a bundle of table chunks and their replicas, spread across multiple shards. If a host shard stumbles during a failover, the system seamlessly switches to a replica shard, which steps up as the new host. It’s all managed automatically—no manual intervention required.

Chunk Set
A chunk is essentially a data block. When you create a table, its partitions are divvied up across multiple shards, which live on different servers. These partitioned chunks form what’s called a chunk set—a collection of data blocks working together to keep everything organized and accessible.
Raft Group
Every shard houses one chunk set, and for each chunk set, replicas exist across multiple shards. Enter the Raft group: a team that keeps track of the leader and its followers. The leader shard calls the shots—handling DML operations—while the follower shards mirror those changes instantly. If a shard leads one replication unit, it plays follower in others, creating a balanced, interconnected system.
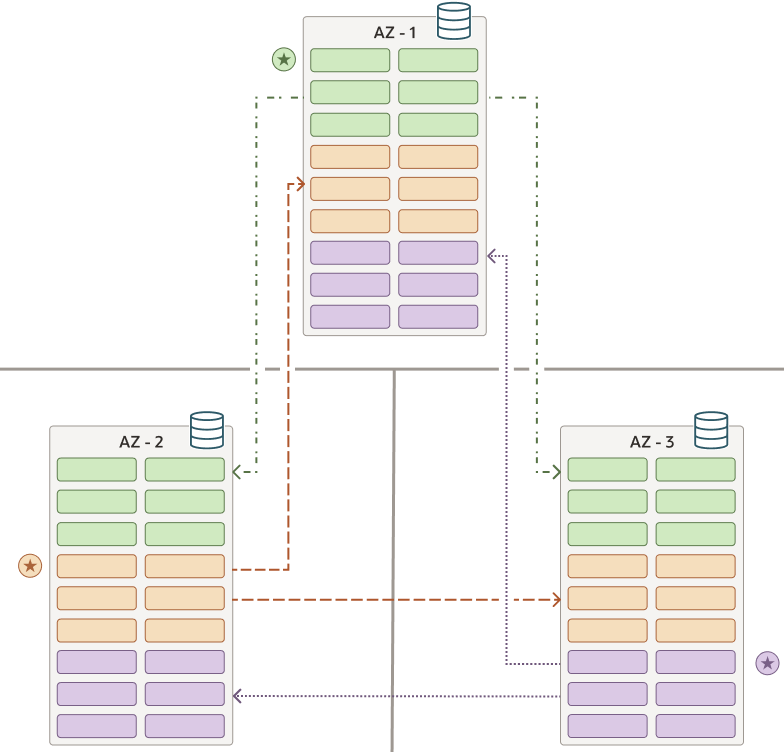
Replication Factor (RF)
The replication factor defines how many shards make up a replication unit: one leader and a set number of followers. For example, with an RF of 3, you get one leader shard and two followers. If one fails, the remaining shards keep the show running, ensuring availability isn’t compromised.
Raft Log
Whenever a transaction hits the leader shard, it’s logged in what’s known as a Raft log. Every shard keeps its own copy of these logs. The moment a transaction is committed on the leader, it’s mirrored in the followers’ Raft logs almost instantly. This tight synchronization slashes failover time, as followers are always ready to step up and take charge. Behind the scenes, OS processes keep these logs humming along.
Leader Election Process
Data flows from the leader to its followers, but what happens if the leader goes down? The followers stop receiving data or the leader’s “heartbeat.” That’s when the Raft protocol kicks in, triggering an election to crown a new leader. By default, the heartbeat checks in every 150 milliseconds. To avoid a chaotic pile-up of simultaneous elections, randomized timeouts (up to 150 milliseconds) can be used. This prevents split votes and keeps the process running like clockwork.
Node Failure
When a node fails, the system jumps into action: shard failover, leadership reassignment, and application reconnection all happen in under 10 milliseconds. For the end user, it’s business as usual—no error messages, just a brief “this might take a moment” pop-up. Once a new leader is in place, the application reconnects, and everything picks up where it left off—all without skipping a beat on the user side.
Leader Node Failure
If the leader shard bites the dust, the Raft protocol steps in to pick a new leader from the healthy follower shards. Once chosen, the client driver—responsible for managing the sharded database—gets the memo and reroutes network traffic to the new leader. Oracle Notification Service (ONS) ensures this handoff is seamless. Meanwhile, the application keeps trying to connect via JDBC. Once the new leader is locked in, the application server resumes normal operations without a hitch.
Failback
What if a failed leader shard comes back online? It reaches out to the current leader of its replica group, syncing up by comparing Raft logs. If the current leader is missing any redo logs, the returning shard syncs with a healthy follower instead. Once it’s up to speed, it rejoins the cluster via the SWITCHOVER RU – REBALANCE API—a neat way to get back in the game.
Follower Node Failure
If a follower shard goes offline, the leader keeps trying to reconnect until it succeeds or a new follower shard is spun up to take its place. The new shard syncs with the leader and other followers, ensuring the replication unit stays intact and operational.
INFOLOB Driving Oracle Database 23ai Implementation
INFOLOB, a leader in Oracle solutions, is well-positioned to harness the power of Oracle Database 23ai’s Raft replication. By implementing this cutting-edge feature, INFOLOB can offer its clients a high-availability database solution that’s both robust and low-maintenance. The self-managing nature of Raft replication—coupled with its lightning-fast failover and active-active design—means INFOLOB can deliver seamless performance, even in the face of unexpected disruptions. For businesses looking to keep their data secure, accessible, and scalable, INFOLOB’s adoption of 23ai is a game-changer, blending innovation with reliability to meet modern demands head-on.
Advantages of INFOLOB-led Oracle Database 23ai
- Seamless Upgrades with Minimal Disruption: We bring a wealth of experience to the table, promising the voyage of Oracle Database 23ai is a smooth ride. From planning and testing to execution, we get into the details thus making your business never skipping a beat with peak performance and zero downtime.
- Tailored High-Performance Solutions: Our experts bring the maximum features of Database 23ai that Oracle offers, customized to your needs for high availability and resiliency. This will accelerate sloppy processes and tackle the most complex workloads.
- Enhanced Security You Can Trust: Oracle offers unbeatable security and Database 23ai’s SQL Firewall and blockchain table enhancements bring enhanced security of all time – for defending against SQL injection attacks and ensuring compliance. Your security is our top priority.
- Scalability That Grows with You: With 23ai’s automated shard rebalancing and active-active replication, they set you up to scale effortlessly. Whether you’re expanding globally or handling a data surge, INFOLOB ensures your system keeps pace without breaking a sweat.
- AI-Driven Insights: We take full advantage of 23ai’s AI Vector Search and JSON Relational Duality Views, putting powerful analytics right where you need them. They help you turn raw data into actionable insights fast—think personalized recommendations or real-time predictions—all without the headache of managing separate systems.
- Cost-effective Implementation: Let’s fine-tune your 23ai implementation to squeeze out every ounce of efficiency, from lock-free concurrency to streamlined resource use. You get top-tier performance without the bloated costs, keeping your budget in check.
- Round-the-Clock Expertise and Support: Disruptions can show up any time and our team offers 24/7 support and ongoing optimization, ensuring your 23ai database stays in tip-top shape and eliminating all the possible disruptions on-time.
- Future-Proofing Your Digital Journey: To step up and future-proof your databases, we integrate features like Transportable Binary XML and advanced automation. This will make your database is ready for tomorrow’s challenges.
The seamless transition and modernization of databases is one click away. Engage us today!


