
Infolob primer on facial recognition and AI
Infolob experts have been at the forefront of AI technologies over the last two years, helping companies solve mission-critical problems with machine learning and video analytics/computer vision solutions. In this series, we will explore foundational components that go into our solutions.
Understanding facial recognition
Facial recognition, or face recognition, is a biometric identification method that analyzes a person’s face, then compares and maps it mathematically to a digital database of face images in order to identify them. Facial recognition technology has seen rapid improvements in the past decade, and algorithms are now able to distinguish faces almost equal to (and sometimes better than) the average human. This blog post and the subsequent ones will be dedicated to giving a complete overview of what exactly facial recognition is and what life-changing applications it has up its sleeve without getting too much into its technical nuances.

Facial recognition is now present in almost every aspect of our life. Mainly used in security and authentication, it is increasingly being used to replace passwords and fingerprints. Ranging from unlocking phones to opening doors, facial recognition is a trusted authentication method because of its ease of use and difficulty to fool. In this post, I’ll give a brief overview of the basics of facial recognition.
Process of facial recognition
The process of facial recognition involves the following:
- Detection and Preprocessing
- Feature Extraction
- Classification
What are detection and recognition?
In order to recognize a person from an image, the system must first detect the face region. This helps us understand the difference between face detection and face recognition.
Face detection:
The process of finding potential face regions in an image or a video frame.
Face recognition:
The process of matching a face region to different face regions in the database to identify a person.
Hence, detection has to be performed first to determine potential ‘faces’ in an image. There are numerous algorithms available that identify faces in an image with maximum precision. We’ll now see how it all started and what’s considered state-of-the-art.
Face detection
Viola-Jones algorithm:
The Viola-Jones algorithm was one of the earliest algorithms for face detection. It is based on a classification algorithm called Haar Cascades, which can be used to classify any object if trained accordingly.
It uses ‘Haar-like features’ to find a face in an image. In simple terms, look at the sample filters shown below, which will be run across the entire image to calculate features.

What are the features?
Features are nothing but some kind of representation of the contents of an image. You have probably heard the term ‘feature extraction.’ In simple terms, consider the problem of comparing a detected face with the faces in the database. One very simple solution is to directly compare the face images pixel to pixel, and if 75% of pixels are the same, we can say that the faces match. But this solution will almost have no efficiency at all because the captured image will be under different lighting conditions, the face may be at a different location in the image, or in a different position, and so on. Therefore, we can’t simply compare every pixel in the image, but we can extract only the useful information, or in other words, information that describes the particular face effectively, and then make a comparison. This information is called a feature. One example of a feature is facial distances. The distances between the eyes and the mouth, between the right and the left eye, and so on, can be calculated and then compared to the database instead of the raw image itself. This, although not the best solution, will improve efficiency.
Coming back to Viola-Jones, the Haar-like features are calculated by running these filters (like in Fig. 1) over the entire image to find potential faces. These filters consider simple intuitive conditions of a face such as:
The first filter in Fig. 1: The eye region is darker than the nose and cheek region.
Second filter in Fig. 1: The eyes are darker than the bridge of the nose.
Thousands of features like these are run throughout the image to detect regions that are potentially a face. Viola-Jones also uses AdaBoost and Cascade of Classifiers to speed up the detection process.

Filters used to calculate features
OpenCV has an implementation of this algorithm, and with this tutorial, anyone with a little programming knowledge can implement a working face detector in minutes.
Dlibs:
One of the most recent, fast, and efficient algorithms includes a library called dlibs. Dlibs is an open-source machine learning library that does quick face detection, pose estimation, and face landmarking.

Data is the most important aspect of developing a machine learning detector. The more data, the more accurate the algorithm becomes. Dlib, however, learns how a face looks with just 18 face samples, as shown below.

After detecting a face/faces in an image, the next step is to extract features and perform the comparison. Traditional machine learning algorithms perform feature extraction using a certain algorithm and then compare images using a different algorithm. The latest technologies, such as deep learning, perform feature extraction and comparison together in a single network. The following steps are usually involved in the recognition process:
Preprocessing:
Simple image processing like alignment, reshaping, and color to grayscale conversion are usually done to prepare the image for feature extraction. The process of cropping the face region from the entire image also falls under preprocessing.

Noisy images on the top and processed images on the bottom – Source
Feature extraction:
Based on the application, different features can be extracted and compared. A few examples are the texture of our faces (lbph), facial distances, etc. These features are extracted from the entire set of database images and then the test image and these features are subject to comparison instead of the entire image itself.

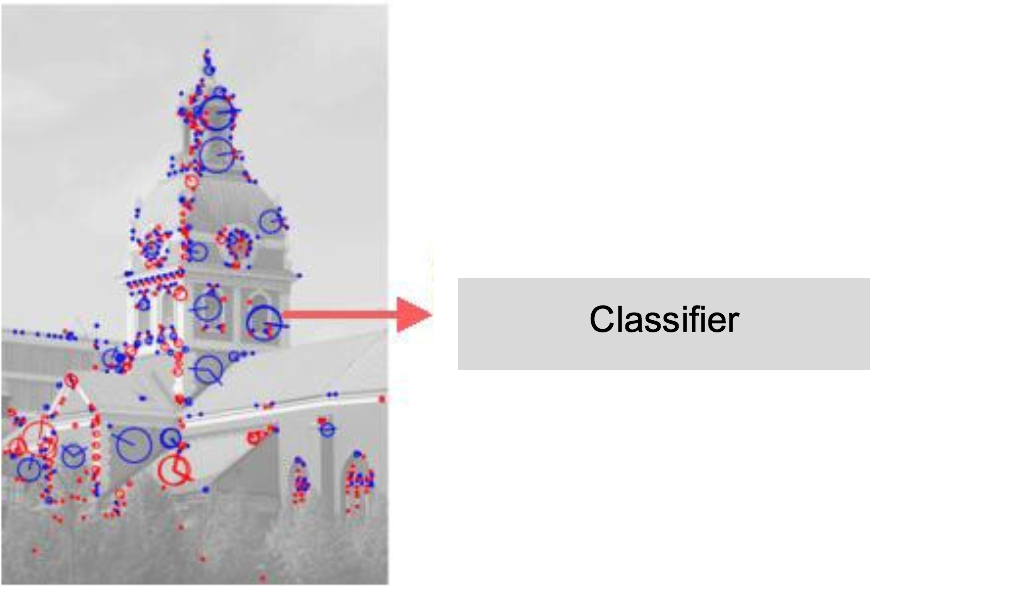 Features extracted from an image: Source
Features extracted from an image: Source
Verification and identification:
Based on our needs, comparing images is done with two different methods.
Verification
Verification is when you have to verify if someone is really who they claim to be.
Identification
Identification is when you have to check if the person is among the list of people you have in the database.
In other words, verification is comparing one test image to the image(s) of one particular person in the database. Identification is comparing one test image to multiple people in the database.

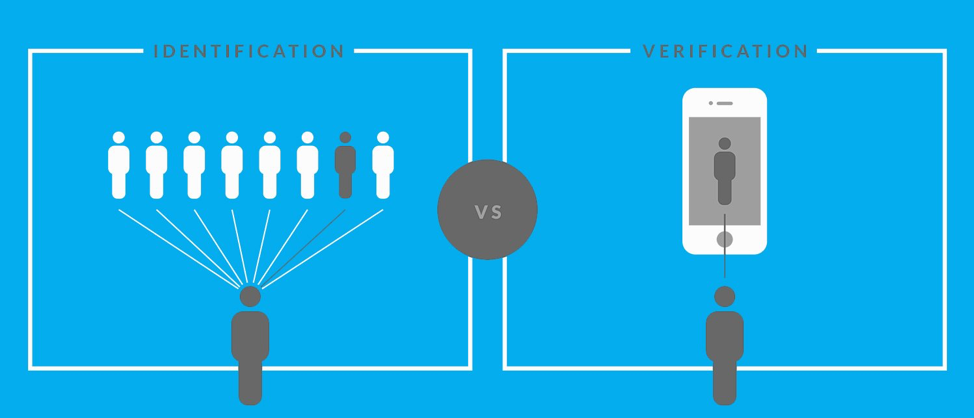 Source: zoloz
Source: zoloz
Deep learning:
With current advancements in deep learning, the introduction of 3D-modeling techniques and image-specific neural networks called Convolutional Neural Networks (CNN), facial recognition has improved by leaps and bounds in terms of ease of development and efficiency.
The advancements and applications of deep learning in facial recognition will be discussed in detail in the second post of this three-post series.
This is the second in a series of posts on deep learning and artificial intelligence by Infolob’s Computer Vision Architect, Sailesh Krishnamurthy. He can be reached at [email protected]. Read his first post here.


